Implementar tu propio ChatGPT localmente, multiples modelos opensource
El proyecto aplicado es para la versión local con tarjeta gráfica integrada, es funcional aunque el tiempo de respuesta no es el acostumbrado frente a los servicios en la web que conocemos. La ventaja es que puede agregar funcionalidades premium como el procesamiento desde documentos o imágenes.
-
Descargar programa Ollama, elegiremos el sistema operativo sobre el que vamos a desplegar, en este caso windows.
Procedemos con la instalación.
-
Instalar Docker
-
Abrir el terminal y ejecutar el siguiente comando. Descargará la imagen webui para docker.
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main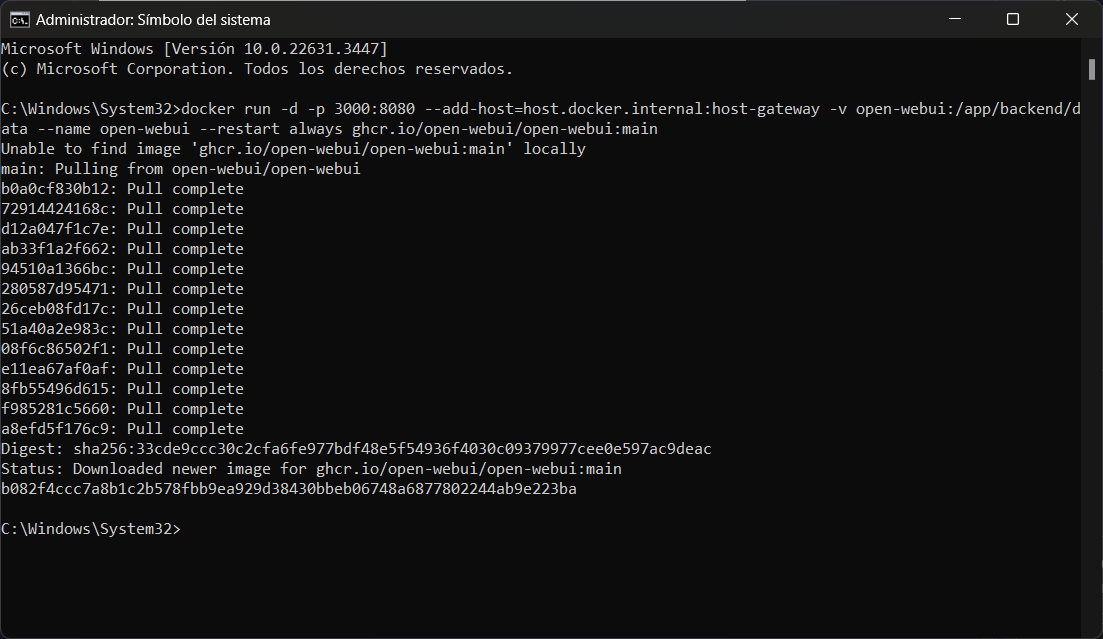
Una vez completado validamos el despliegue ingresando desde el navegador a http://localhost:3000 -
Creamos una cuenta local (Sign up) para conectarnos.
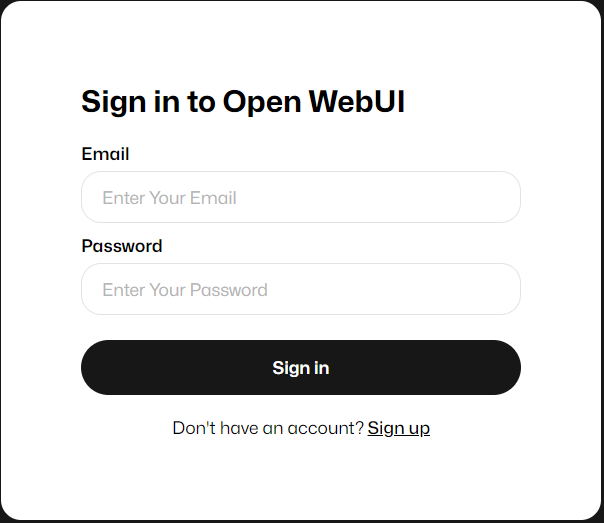
-
Para instalar cualquier modelo es necesario realizarlo desde la terminal. La lista de modelos disponibles están aquí
ollama pull nombremodeloEl modelo será descargado.
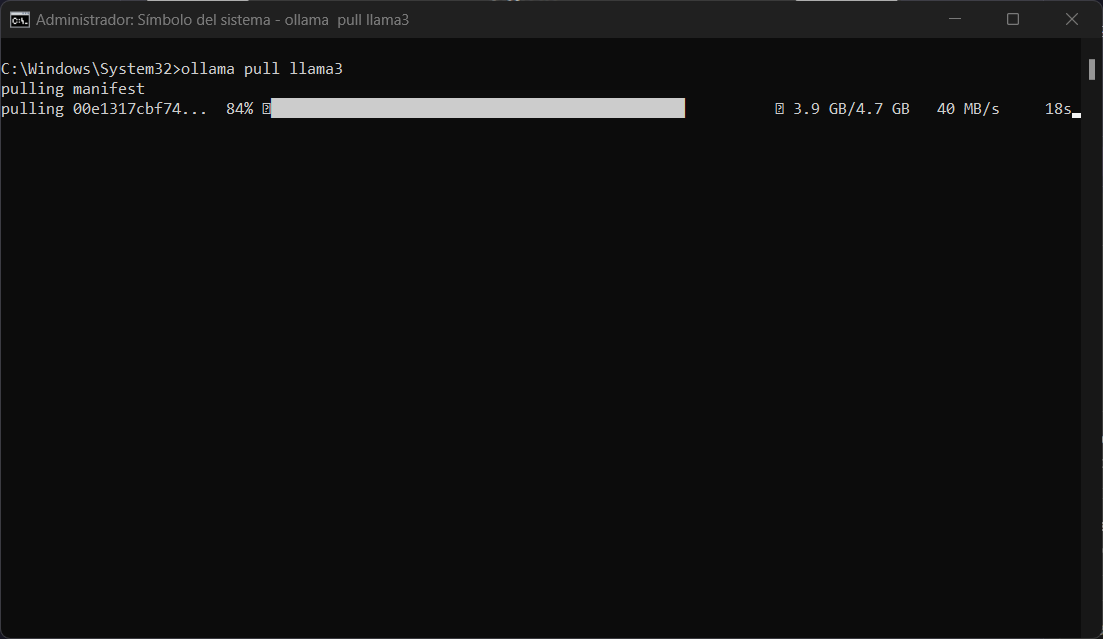
Al concluir dentro de la interfaz web podremos elegir el modelo que se desee usar.

-
Configuraremos modelos mediante apikey de OpenAI.
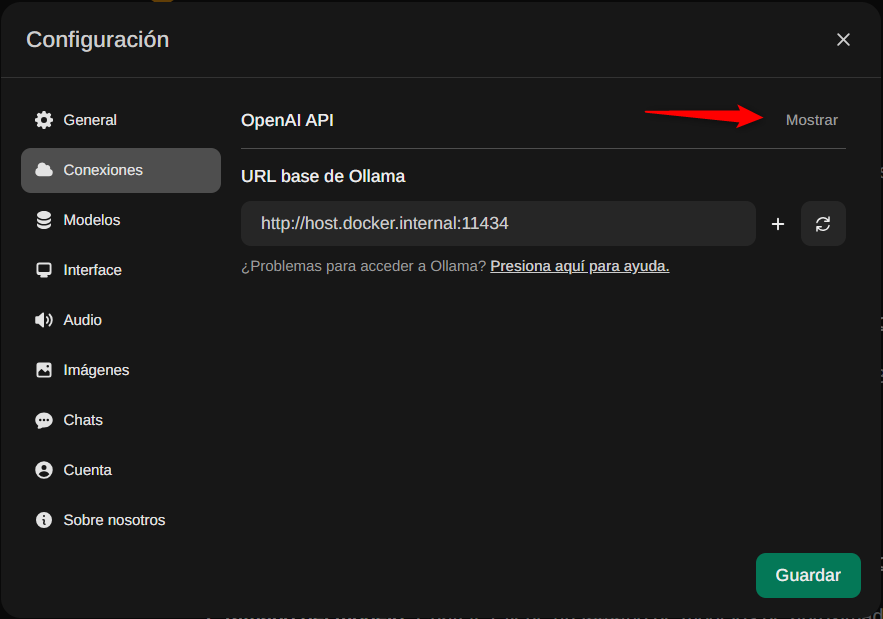
Colocamos la clave y Guardamos
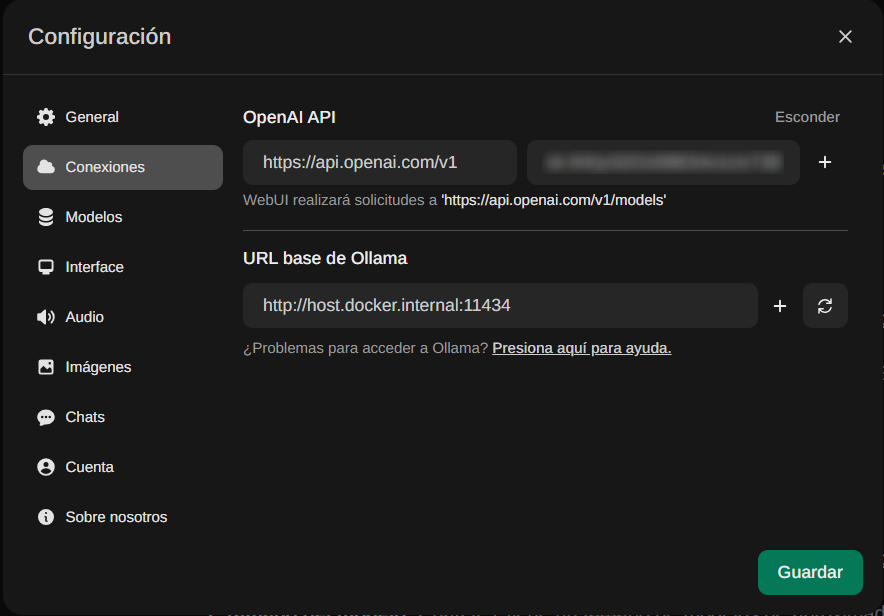
Lo tendremos disponible para usar en cualquier chat
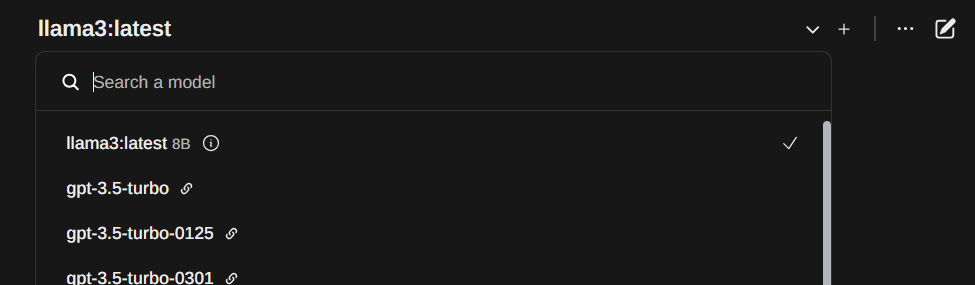
-
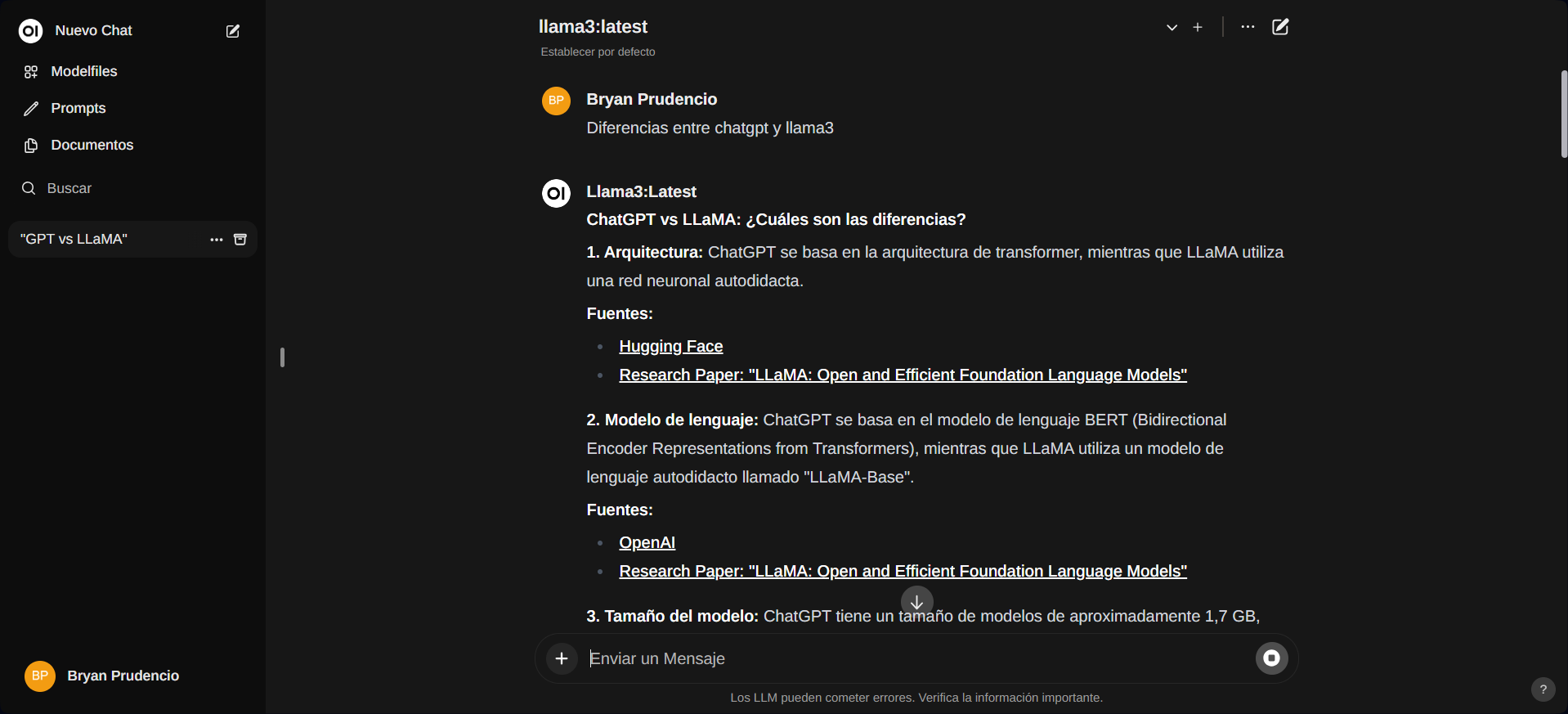
Ya puedes administrar tus chats y personalizarlos.
Si este artículo te sirvió agradecería puedas apoyarme con un café.
